
Das Ziel vieler Spritzgiessverarbeiter ist es, einen Schritt Richtung vollständiger Automatisierung des Spritzgiessprozesses zu gehen („lights-out manufacturing“). Der Einsatz von Machine Learning (ML) bietet hierzu eine interessante Möglichkeit. Anomalien im Prozess sollen selbständig von einem ML-System erkannt werden, ohne die Hilfe eines erfahrenen Menschen, sondern nur anhand von Daten.
Autor: Curdin Wick, Fachbereichsleiter Spritzgiessen, IWK
Die Daten des Spritzgiessprozesses sind für diesen Zweck gut geeignet, da der Prozess inhärent zyklisch ist und mit den aufgezeichneten internen Maschinensignalen genügend Informationen vorhanden sein sollten, um die Qualität eines Bauteils vorauszusagen.
Der heutige Spritzgiessprozess zur Produktion von fertigen Kunststoffbauteilen ist ein sehr komplexer Vorgang. Es sind viel Erfahrung und Fachwissen notwendig, um qualitativ hochwertige Bauteile herzustellen. Änderungen in Kunststoff-Chargen, Umwelteinflüsse und verschleissbedingte Veränderungen an Maschinen- und Werkzeugkomponenten können die Qualität der Formteile stark beeinflussen. Daher benötigt eine Spritzgiessmaschine einen erfahrenen Verfahrenstechniker, welcher auf sich ändernde Eingangsgrössen Gegenmassnahmen einleiten kann. Moderne Maschinen können diese Gegenmassnahmen aufzeichnen und haben zudem Zugriff auf eine enorme Fülle von internen Maschinendaten. Somit sollte es für ein geeignetes Machine Learning Verfahren möglich sein, diese Gegenmassnahmen automatisch zu erlernen und aufgrund der grossen Menge an internen Messsignalen, Prozessanomalien vorausschauend zu erkennen. Wenn ein Verfahrenstechniker eingreift, wird die Beziehung zwischen der Einstellaktion und der Anomalie gelernt, so dass das ML-System in Zukunft frühzeitig Prozessoptimierungsvorschläge machen kann. Dies ist ein fundamental neuer Prozessmanagementansatz, da der Algorithmus schon Probleme erkennen kann, welche für den Verfahrenstechniker noch nicht sichtbar sind und gleichzeitig auch Einstellmassnahmen vorschlägt, welche er durch Generalisierung der beobachteten Massnahmen von Verfahrenstechnikern automatisch abgeleitet hat.
Voruntersuchungen zum Einsatz von Machine Learning
In einer Machbarkeitsstudie wurden am IWK erste Untersuchungen zum Einsatz von Machine Learning beim Spritzgiessen durchgeführt. Die verwendete Spritzgiessmaschine PX120-380 von KraussMaffei verfügt über einen integrierten DataXplorer, welcher die Aufzeichnung der Maschinensignale während des kompletten Zyklus als Kurvendaten ermöglicht, wie z.B. Temperaturen, Drücke, Leistungen, Steuersignale, Geschwindigkeiten und Positionen. Dadurch resultieren rund 300’000 Datenpunkte pro Zyklus, welche dann für die Auswertung und Bildung von Modellen zur Verfügung stehen.
Für diese ersten Untersuchungen wurde ein Eiskratzer (Bild 1) als Versuchsbauteil eingesetzt. Ausgehend von einem guten Betriebspunkt wurden gezielt Störungen eingebracht, welche so auch in einem realen Produktionsbetrieb auftreten können:
- Versuchsreihe 1 (72 Bauteile) – Referenz Versuchsreihe. Einstellungen so gewählt, dass die Eiskratzer innerhalb der Toleranzen liegen.
- Versuchsreihe 2 (56 Bauteile) – Nachstellung, z.B. verkalkte Kühlkanäle: Temperatur des Mediums der Werkzeugtemperierung erhöht
- Versuchsreihe 3 (57 Bauteile) – Nachstellung, z.B. Chargenschwankung: Zylindertemperatur erhöht
- Versuchsreihe 4 (52 Bauteile) – Nachstellung, z.B. falscher Kunststoff: 10% Fremdmaterial hinzugefügt
Als Kunststoff wurde das Material Polypropylen HF955MO verwendet. Für jeden Versuch wurden die entsprechenden Qualitätsmerkmale der hergestellten Bauteile gemessen (siehe Bild 1).
Aus den aufgezeichneten Maschinendatenkurven wurden verschiedene Features berechnet. Ziel ist es dadurch die Datenmengen möglichst ohne Informationsverlust zu reduzieren. Natürlich sind auch Ansätze ohne händisches Feature Engineering denkbar, dafür muss die Anzahl an Daten jedoch deutlich erhöht werden. In diesem Fall wurden die Features mit Hilfe verschiedener aus der Statistik bekannten Formeln berechnet. Es ist hier auch denkbar auf Fachwissen aus der Spritzgiessverarbeitung zurückzugreifen und mit bekannten Grössen (z.B. max. Spritzdruck, Fliesszahl, Integral Werkzeuginnendruck, etc.) zu arbeiten. Diese statistischen Features und die ermittelten Qualitätsmerkmale wurden für das Training der Modelle verwendet.
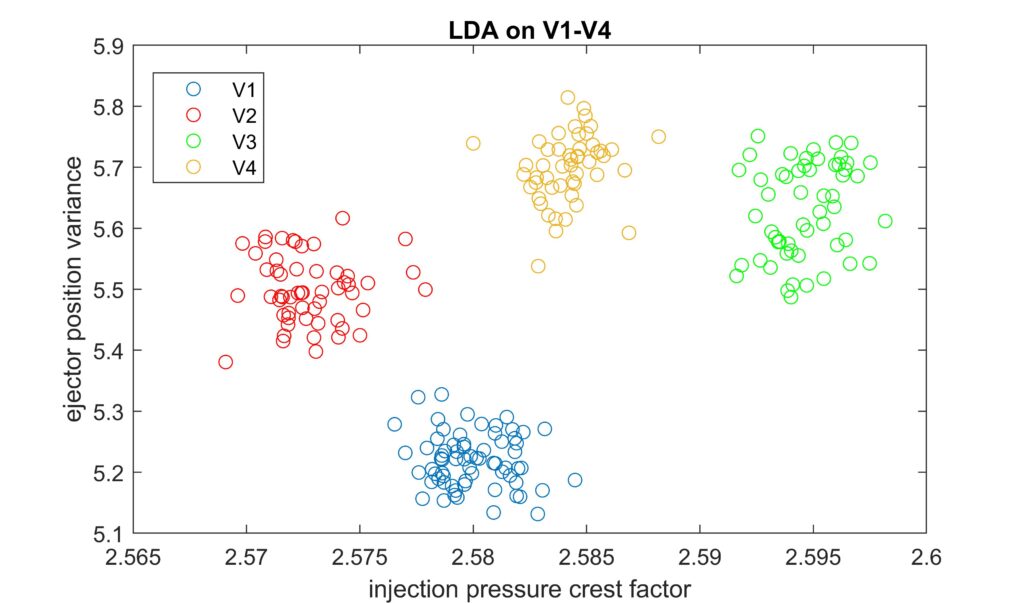
In einem ersten Schritt wurde analysiert, mit welchen und wie vielen Features sich die einzelnen Testreihen klassifizieren lassen. Um herauszufinden, welche Features hierbei den grössten Einfluss haben, wurde eine Forward Stepwise Selection ausgeführt. Als Resultat liefert dieses Verfahren eine geordnete Liste von geeigneten Features. Die Daten aus den Testserien V1-V4 können mit bloss zwei dieser Features vollständig getrennt werden. Ein Beispiel für Features, welche diese Trennung sehr gut ermöglichen, sind in Bild 2 dargestellt. Dabei wurde für die eigentliche Klassifizierung der Versuchsreihen eine Linear Discriminant Analysis (LDA) benutzt.
Das heisst wenn die Testserien mit Hilfe von nur zwei Features so eindeutig klassifiziert werden können, so sollten auch Anomalien in der Produktion zuverlässig erkannt werden können.
Die entwickelten Modelle wurden zudem weiter an Testserien (zufällige Daten aus den Versuchsreihen, welche nicht für die Entwicklung und das Training der Modelle verwendet wurden) getestet, in dem die Qualitätsmerkmale dieser Bauteile vorausgesagt werden konnten. Die Ergebnisse sind in Bild 3 dargestellt.

Die relative Genauigkeit (Standardabweichung/Mittelwert) dieser Vorhersagen ist besser als 1% für Bauteile, welche nicht in der Trainingsmenge waren (Bauteile, für welche der Algorithmus keine Qualitätsangaben erhalten hat). So wurde in diesen Voruntersuchungen mit Absicht 10% Fremdmaterial beigefügt, um eine Chargenschwankung zu simulieren. Dem Algorithmus werden keine Informationen zur Charge zugänglich gemacht und dennoch kann dieses Verfahren die obige relative Genauigkeit immer noch erreichen.
Grundsätzlich werden die Modelle auf neuen unbekannten Testserien besser, wenn sie mit mehr Daten trainiert werden. Die einfachste Methode, um die Qualität noch weiter zu verbessern, ist demnach mehr Daten hinzuzufügen. Auch gibt es noch Potenzial die Modelle weiter zu verbessern. Eine Analyse mit höherdimensionalen Regressionsmodellen könnte ebenfalls zu einer Verbesserung führen.
Ausblick und Herausforderungen
Ziel der nächsten Schritte ist die Übertragung auf andere Bauteile, Materialien und Maschinen sowie die Vorhersage der geeigneten Gegenmassnahme bei auftretender Anomalie. Deshalb läuft am IWK seit zwei Jahren ein von der Innosuisse gefördertes Projekt mit fünf Industriepartnern zur vertieften Untersuchung dieses Themas. Dabei zeigte sich, dass die Datenbasis einer der grössten Erfolgsfaktoren für die Umsetzung eines ML-basierten Prozessmanagementsystems ist. Das heisst die internen Daten der Spritzgiessmaschinen müssen in der geforderten Qualität aufgezeichnet werden können. Zum einen werden dafür maschineninterne Daten (Prozessdaten) benötigt, zum anderen werden aber auch Einstellparameter und Qualitätsdaten der Bauteile benötigt, um ein multifunktionales System aufzubauen. Da die Qualitätsdaten der produzierten Teile oft nicht verfügbar sind, sollte daher zumindest der Grund für die Prozessanpassung festgehalten werden. Die am Markt verbreiteten Schnittstellen Euromap 63 und Euromap 77 (OPC-UA) bieten eine Möglichkeit für einen schnelleren, einfacheren und standardisierten Datenaustausch sind aber bezüglich Abtastraten für einen Livebetrieb limitiert.
Kontakt
IWK Institut für Werkstofftechnik und Kunststoffverarbeitung
Curdin Wick
OST Ostschweizer Fachhochschule
Eichwiesstrasse 18b
CH-8645 Rapperswil-Jona
www.iwk.hsr.ch